Bootstrapped Transformer for Offline Reinforcement Learning
Arxiv: https://arxiv.org/abs/2206.08569
Code: https://github.com/microsoft/autorl-research
Authors
- Kerong Wang (Shanghai Jiao Tong University) wangkerong@sjtu.edu.cn
- Hanye Zhao (Shanghai Jiao Tong University) fineartz@sjtu.edu.cn
- Xufang Luo (Microsoft Research Asia) xufluo@microsoft.com
- Kan Ren (Microsoft Research Asia) renkan@shanghaitech.edu.cn
- Weinan Zhang (Shanghai Jiao Tong University) wnzhang@sjtu.edu.cn
- Dongsheng Li (Microsoft Research Asia) dongsli@microsoft.com
Abstract
Offline reinforcement learning (RL) aims at learning policies from previously collected static trajectory data without interacting with the real environment. Recent works provide a novel perspective by viewing offline RL as a generic sequence generation problem, adopting sequence models such as Transformer architecture to model distributions over trajectories, and repurposing beam search as a planning algorithm.
However, the training datasets utilized in general offline RL tasks are quite limited and often suffer from insufficient distribution coverage, which could be harmful to training sequence generation models yet has not drawn enough attention in the previous works. In this paper, we propose a novel algorithm named Bootstrapped Transformer (BooT), which incorporates the idea of bootstrapping and leverages the learned model to self-generate more offline data to further boost the sequence model training.
We conduct extensive experiments on two offline RL benchmarks and demonstrate that our model can largely remedy the existing offline RL training limitations and beat other strong baseline methods. We also analyze the generated pseudo data and the revealed characteristics may shed some light on offline RL training.
Algorithm Overview
The overall idea of our BooT algorithm is to utilize self-generated trajectories as auxiliary data to further train the model, which is the general idea of bootstrapping. We divide BooT into two main parts, (i) generating trajectories with the learned sequence model and (ii) using the generated trajectories to augment the original offline dataset for bootstrapping the sequence model learning.
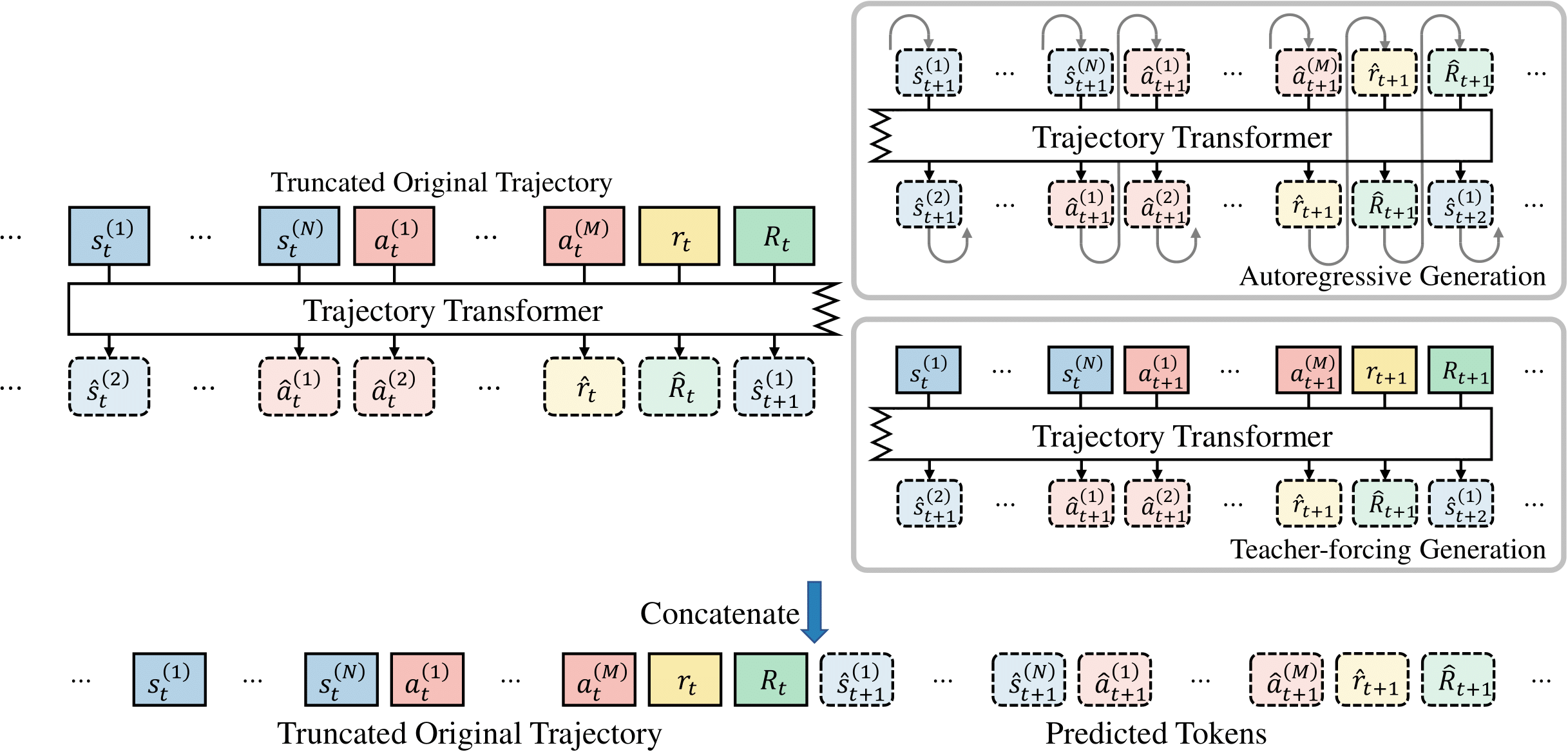
Basically, for each batch of input trajectories, we first train the model with original trajectories. We then generate new trajectories based on the original trajectories, filter them with their quality, and finally train the model again with the generated trajectories. The trajectory generation procedure is demonstrated in the figure above.
Experiment Results
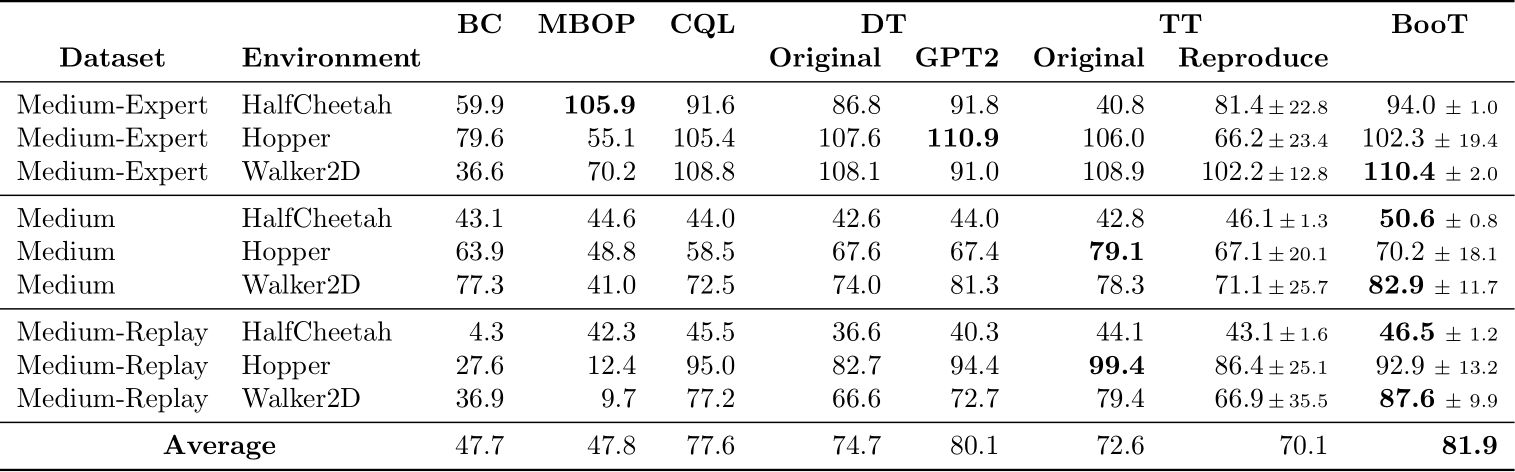
We evaluate the performance of BooT algorithm on the dataset of continuous control tasks from the D4RL offline dataset. We compared BooT to various baselines as shown in the table.
Further Analysis of Bootstrapping
To better understand how BooT helps improve the performance, we visualize the distribution of transitions in the (i) original data, (ii) from teacher-forcing generation, and (iii) from autoregressive generation in BooT. We reduce them to 2-dimension via t-SNE altogether, and plot them separately.

The overall results demonstrate that generated trajectories from BooT expand the data coverage while still keeping consistency with the underlying MDP of the corresponding RL task, thus resulting in better performance compared to the baselines.
Related Works
Offline Reinforcement Learning as One Big Sequence Modeling Problem