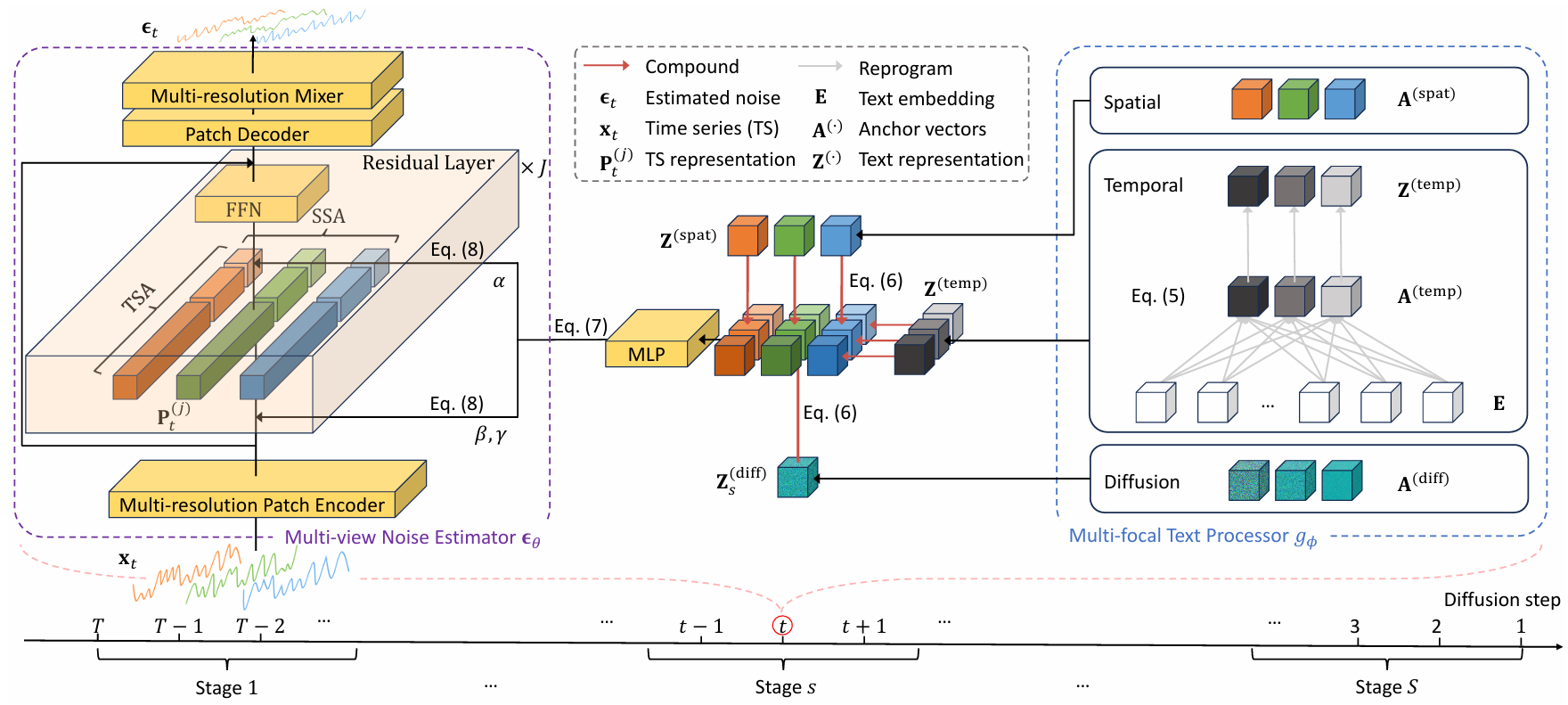
Time series synthesis has become a foundational task in modern society, underpinning decision-making across various scenes. Recent approaches primarily generate time series from structured conditions, such as attribute-based metadata. However, these methods struggle to capture the full complexity of time series, as the predefined structures often fail to reflect intricate temporal dynamics or other nuanced characteristics. Moreover, constructing structured metadata requires expert knowledge, making large-scale data labeling costly and impractical. In this paper, we introduce \method, a novel framework for generating time series from unstructured textual descriptions, offering a more expressive and flexible solution to time series synthesis. To bridge the gap between unstructured text and time series data, \method employs a multi-focal alignment and generation framework, effectively modeling their complex relationships. Experiments on two synthetic and four real-world datasets demonstrate that \method outperforms existing methods in both generation quality and semantic alignment with textual conditions.
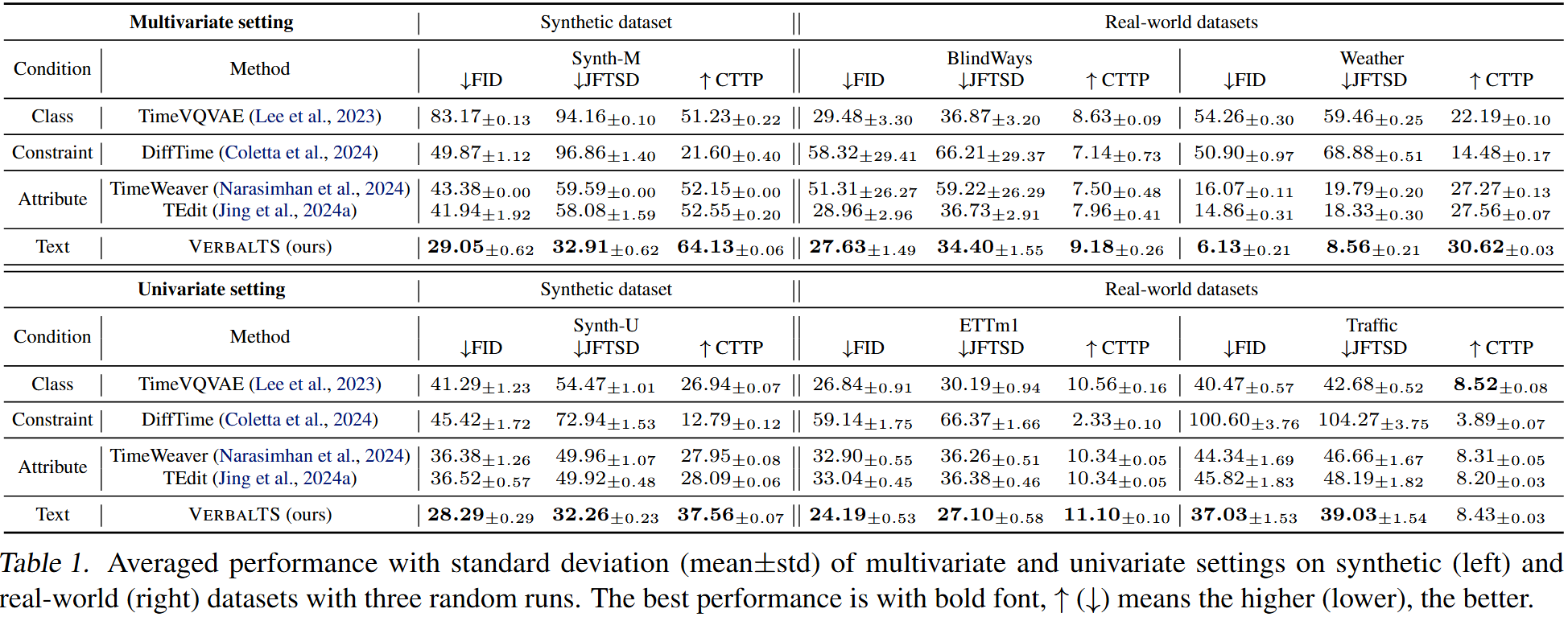
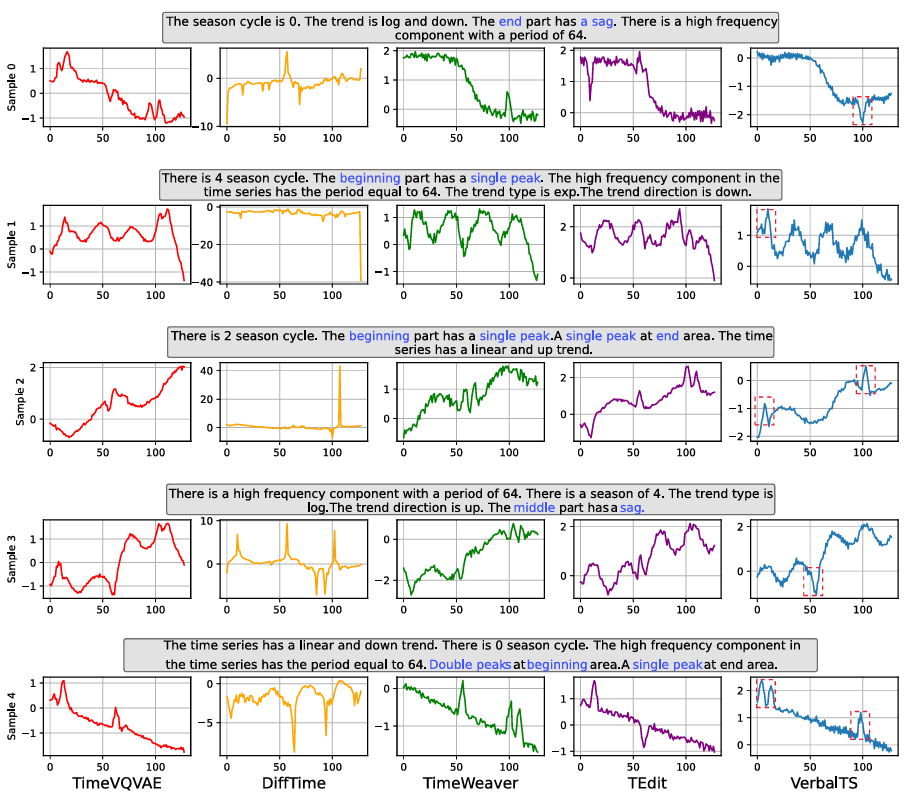
We compare our method VerbalTS with baselines on two full synthetic datasets, two real-world datasets, and two augmented real-world datasets. VerbalTS demonstrates the ability to generate high-quality time series that are semantically well-aligned with the given conditions.
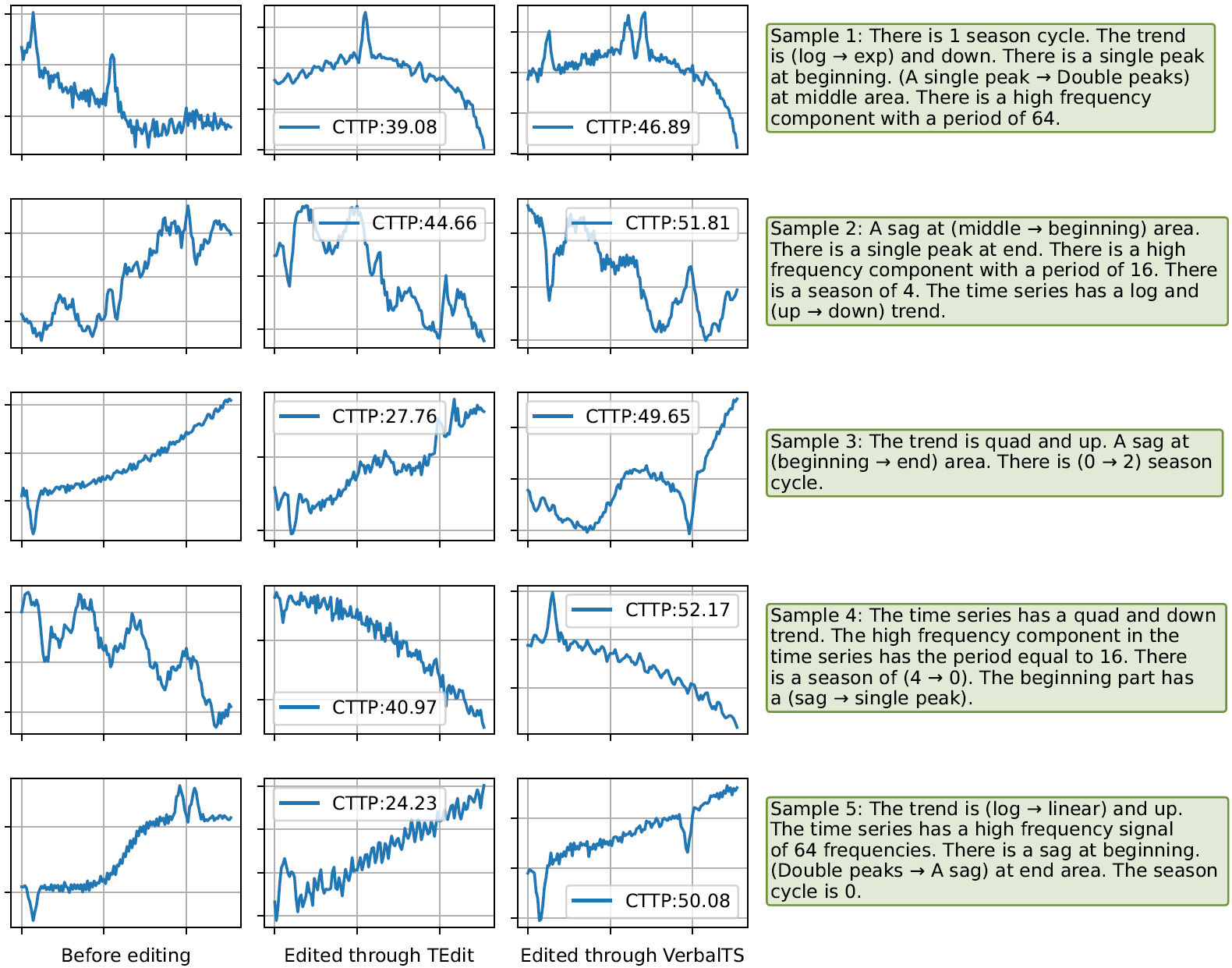
Our method retain original text characteristics while aligning with modified descriptions. With the unstructured text descriptions, VerbalTS achieves finer edits by precisely locating and following the adjusted tokens in the target text description.
@article{gu2025verbalts,
author = {Gu, Shuqi and Li, Chuyue and Jing, Baoyu and Ren, Kan},
title = {VerbalTS: Generating Time Series from Texts},
journal = {International Conference on Machine Learning},
year = {2025},
}